


Начинающие авторы часто сталкиваются с завышенной тошнотой текстов. Она выражает заспамленность или частое повторение одинаковых, однокоренных слов. Причиной является неопытность и недостаточный словарный запас, который не позволяет быстро находить правильные слова для выражения конкретной мысли в тексте. SEO-оптимизация использует такие понятия, как классическая и академическая тошнота текста. Показатели придуманы разработчиками фильтров опираясь исключительно на существующий контент с сайтов — лидеров ТОП-выдачи.
On-page SEO больше не удовлетворяется простым использованием ключевых слов. Соответствие ключевых слов намерению пользователя критически важно.
Rand Fishkin


Невозможно достичь идеального параметра по данным критериям. Их не знает никто, но есть установленные нормы, на которые нужно равняться при написании качественного текста. Создавая новый «шедевр», не стоит забивать голову научными понятиями, пытаясь одновременно подтянуть работу к нормативам. Это зачастую вынуждает выполнять дополнительные действия по доведению заспамленности до нормального значения.
Современные поисковые алгоритмы анализируют не только частоту повторений, но и семантику контента.
Главное – естественность и релевантность запросу пользователя.
Опытные наборщики текстов, проработавшие за печатными станками много лет, достигли определенного профессионализма. И все равно часто приходится проводить проверку с доведением всех показателей до нормальных значений.
Разновидности
Существует много различных инструментов для проверки текстовых работ на заспамленность. Всеми используется похожий принцип, но есть определенные отличия, зависящие от реализованных механизмов анализа. Некоторые сервисы проводят проверку тошноты текста по двум критериям:
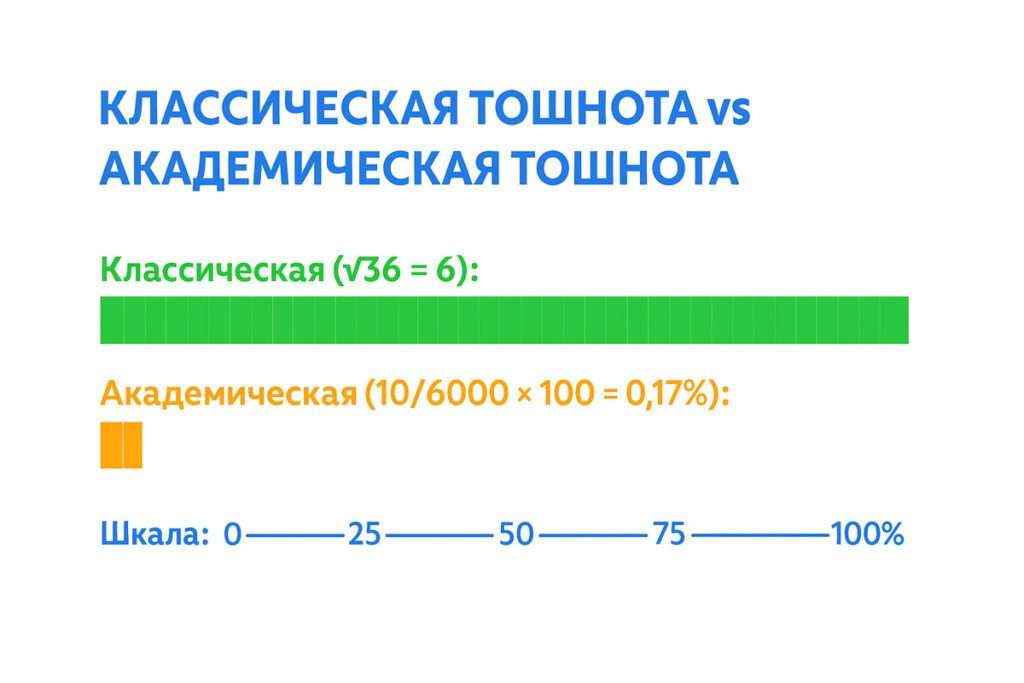
- Классическая тошнота. Она рассчитывается как квадратный корень из общего количества однокоренных слов. Например, если было использовано 36 слов «область» в разной словоформе, то показатель будет равен 6.
- Академическая тошнота рассчитывается как отношение часто используемых слов к общему объему проекта. Допустим, если объем текста составил 6 тыс. символов, а слово «дверь» встречается 10 раз, то показатель будет равен 10/6000 или 0,06. Число является процентной величиной; следовательно, его нужно умножить на 100, и тогда результат станет равен 6%.
Исследование Authority Hacker показало, что плотность ключевых слов по-прежнему коррелирует с более высокими позициями в поисковой выдаче.

Логично спросить, зачем нужны эти показатели? В сети публикуется немало статей со схожей тематикой. Естественно, возникает необходимость их сортировать. На основе существующих работ делается анализ и выводятся нормативы. Если текст не входит в него по этому показателю, то поисковый робот блокирует контент путем наложения фильтра Баден-Баден, который используется поисковиком Яндекс.
Google ужесточил борьбу с веб-спамом, что усложнило нарушителям восстановление после применения санкций.
Rand Fishkin
Поисковики Яндекс и Google обращают внимание не только на тошноту текста, но на ряд других факторов. Например, на ключевые слова, фразы, объем текста и многое другое. Узнать как составить текст так, чтобы ваш сайт попал в ТОП выдачи можно с помощью онлайн-инструмента Текстовый анализатор.
| Параметр | Норма | Влияние на SEO |
| Количество символов | 1000-5000 | Высокое |
| Количество слов | 300-1500 | Высокое |
| Классическая тошнота | До 7% | Критическое |
| Академическая тошнота | 7-9% | Критическое |
| Количество стоп-слов | 40-60% | Среднее |
| Водность | До 30% | Среднее |

Нормативы
Что такое норма? Это оптимальное количество повторений слов. Для академической и классической тошноты они установлены свои:
- Для первой нормой является 7-9% при использовании сервиса Адвего, около 7% для Миратекст и не более 45% в системе Текст.ру.
Так что вместо того, чтобы набивать текст ключевыми словами как можно больше, старайтесь писать естественно.
John Mueller Google
- Для классической тошноты показатель не должен превышать 7%. Он проверяется при помощи инструментов Адвего-сервиса. Чем меньше, тем лучше, но достичь 3% редко сможет даже опытный копирайтер.
- СЕО-оптимизация заключается в постоянной борьбе с конкурентами, то есть контент сайта нужно сделать максимально приближенным к нормативам. Для этого рекомендуется выполнить анализ сайтов конкурентов. Зная их показатели, можно составить семантическое ядро для своей работы.
Большинство экспертов рекомендуют поддерживать плотность ключевых слов на уровне 1-2% от общего объема текста.
Важно! Чтобы увидеть всю заспамленность текста, его необходимо внимательно вычитать; при этом не стоит забывать о том, что чем больше сидишь над текстом, тем больше в нем будет допущено тавтологий.
Методы снижения тошноты
Даже опытные копирайтеры тратят много времени на адаптацию своего только что созданного «шедевра». Как правило, у них показатели не сильно выходят за допустимые пределы. По этой причине удаление нескольких слов «такое» или «и» помогает быстро привести его к норме.

Да, кстати, существует также показатель повторения по отдельным словам. В Адвего он указывается в разделе «Семантическое ядро», выражается в процентах. Здесь же отмечается количество повторений. На примере видно, что слово «текст» встречается 16 раз, что составляет 2,86%. Это много, а потому цифру следует уменьшить хотя бы до 2% — тогда изменится академическая тошнота. Классическая тошнота составляет у фрагмента 4,00, а академическая 8,5%, что является нормой.
Перед снижением тошноты в своей работе, необходимо удалить из нее явные орфографические и прочие ошибки. После чистки, как правило, показателями увеличиваются.
По окончании редактуры можно приступить к оптимизации под приведенные показатели. При этом можно использовать несколько методов.
Чрезмерное увлечение снижением тошноты может привести к потере смысла текста.
Помните: качество контента важнее идеальных показателей.


конверсии вашего сайта
в Яндекс-Директ


Уже скачали 1348 раз
Замена или удаление часто встречающихся слов и фраз
Осуществите анализ работы в том же Адвего и оптимизируйте текст по таблицам из раздела «Семантическое ядро». Проверять часто встречающиеся слова удобно при помощи инструментов Текст.ру: сервис подсвечивает их разными оттенками и указывает точное количество таких слов в таблице.

Увеличение объема работы
Делать это нужно внимательно, потому что с ростом количества слов часто генерируются нежелательные повторения. В любом случае, увеличение числа символов по отношению к повторяющимся фразам приводит к снижению показателей.
В нашем примере академическая тошнота составила 8,5%, а классическая — 4,00. Это входит в рамки нормы, но текст можно улучшить. К примеру, понизить тошноту до 7,5% или 7%. Также не забываем про повторения слов/фраз, уменьшая все показатели ниже 2% с сохранением смысла.
Сначала следует избавиться от ненужных повторений слов «текст» и «тошнота». Следом за ними пойдут короткие слова «и», «на» и т.д. Нередко после всех манипуляций с изменением количества повторений слов текст становится заметно меньше. Тогда приходится дописывать смысловые блоки, избегая дополнительных ошибок.
После применения ранее указанных методов результат налицо. Академическая тошнота снизилась до 8%, а классическая — до 3,00. Одновременно с ними показатель количества повторений слов/фраз упал ниже 2%.

Наши действия заключались в удалении лишних слов и изменении предложений. По новым показателям текст пройдет проверку и не будет отправлен под фильтр.
Методы снижения классической тошноты
Как уже было сказано, этот показатель является соотношением часто встречающихся слов к общему объему работы. Робот действует просто. Если одно слово повторяется более 15 раз — значит, статья переспамлена. Для снижения этого параметра применяется 2 способа:
- Удаление повторов. Используем сервис Текст.ру, чтобы увидеть количество и плотность спамных слов. Также этот показатель хорошо просматривается в семантическом ядре Адвего.
- Удаление стоп-слов. К ним относятся не несущие смысловой нагрузки слова. Текст получается насыщенным деепричастиями, потому что вместо них пришлось бы вставить слово «которые». Увеличение объема всегда влечет за собой рост классической тошноты. Об этом нужно помнить, так как придется понижать и ее.
С завышенным количеством тематических слов разобрались, но что делать, если их слишком мало? Тогда поисковый робот может посчитать, что статья не отвечает на запрос и она окажется под действием фильтра. Для увеличения тошноты на 1 пункт достаточно добавить пару тематических слов.
Проверка на заспамленность
Все действия, описанные ранее в этой статье, можно выполнить вручную при вычитке. Ненужные слова заметно ухудшают качество и восприятие произведения или научной работы.
Важно знать, что после прочтения нескольких статей ошибки в последующих работах будут пропускаться из-за усталости и снижения внимания. По этой причине стоит прибегать к помощи третьих лиц, но лучше воспользоваться специально созданными инструментами.
В 2024 году поисковые системы внедрили факторы семантического поиска для понимания запроса и намерений пользователя: контекст пользователя, обработка естественного языка, контекст потока запросов и распознавание сущностей.
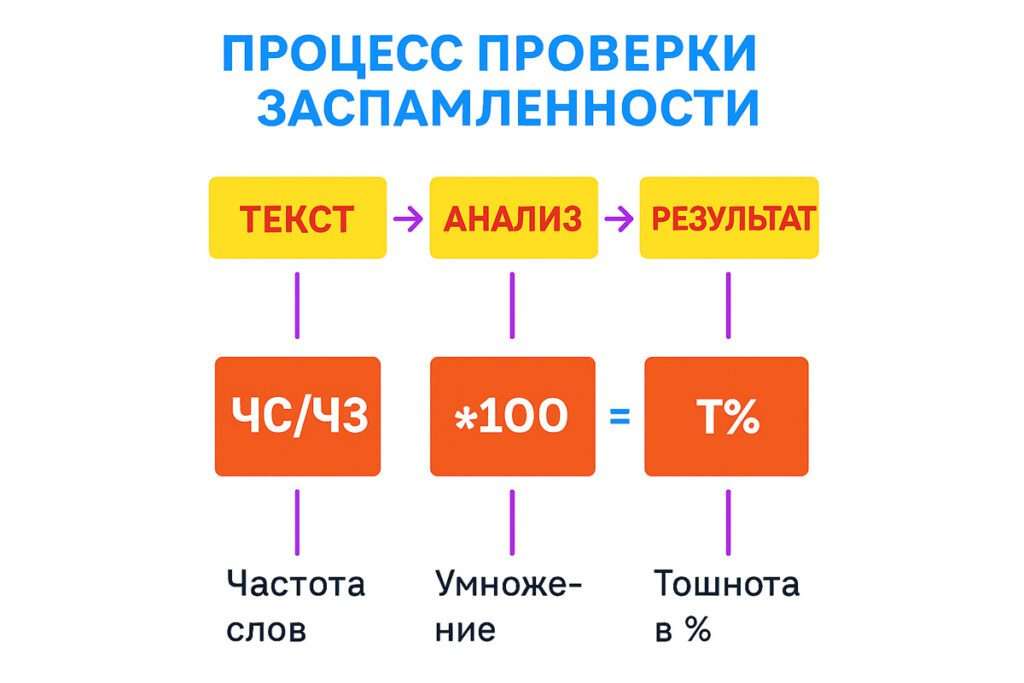
Заспамленность, как любой другой параметр, можно определить через формулу:
ЧС/ЧЗ*100=Т%, где
ЧС — частота слов,
ЧЗ — обще число знаков,
Т% — тошнота.
Существуют специализированные инструменты, с помощью которых можно определить:
- академическую и классическую тошноту;
- уровень воды;
- заспамленность и прочие показатели.

На изображении выделена заспамленность. Показатель до 50% поисковыми роботами считается нормой, и статья проходит проверку.
Дополнительные проверки
Существует анализ текста по закону Ципфа, получивший название PR-CY. Он определяет пропорциональность расположения конкретного слова.
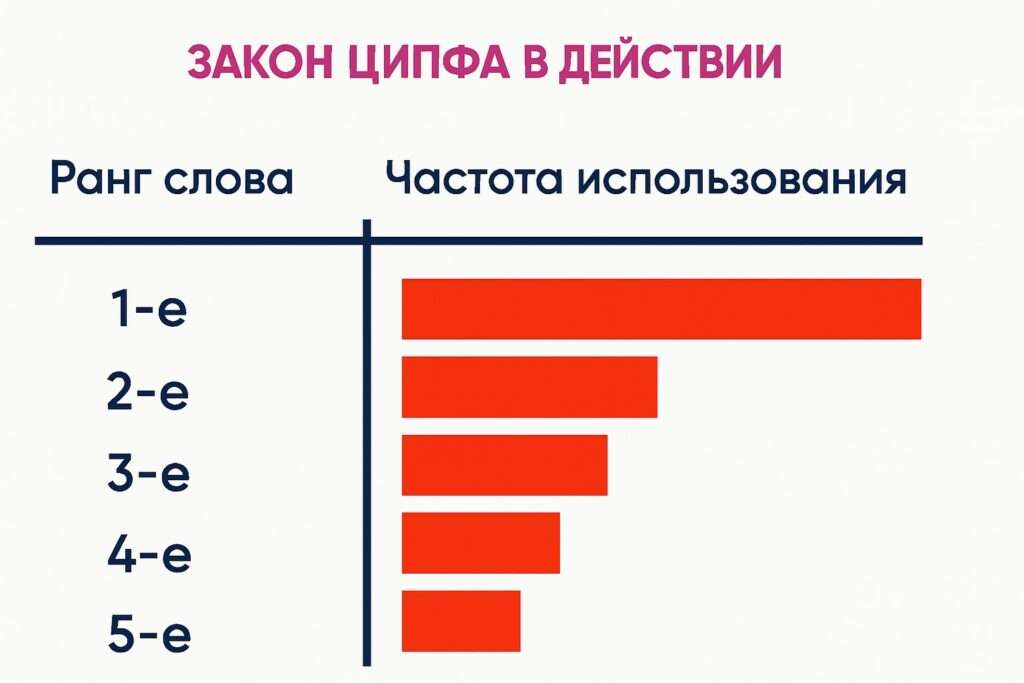
Здесь справедливо вспомнить про приоритет или значимость ключевых слов. Каждое последующее имеет значимость на 1 порядок ниже и стоит в тексте на следующем месте после предыдущего, более значимого.
Определить показатель по закону Ципфа в документе можно на сайте PR-CY. Нужный сервис находится во вкладке «Инструменты».
Искусственный интеллект значительно повлиял на SEO-копирайтинг, инструменты вроде GPT-4 и другие продвинутые языковые модели используются для генерации контента.


Сервис позволяет проверять готовые страницы или отдельный документ. Его объем может составлять до 15 тыс. символов. Нормальной по этому закону считается тошнота до 7%. У нас в тексте она составила 5,74%, что очень хорошо.

Также инструмент в столбце «Рекомендации» показывает, сколько нужно добавить или убавить слов для соответствия. Чем ближе к 100%, тем качественнее написана работа.
✅ Оптимальная плотность ключевых слов: 1-2%
✅ Качество контента важнее точных показателей
✅ Современные алгоритмы анализируют семантику
✅ Регулярный контроль помогает избежать фильтров









А тошнота разве имеет вес при ранжировании?