Сервис собирает данные из Yandex.Wordstat – данные левой и правой колонки по заданному ключевому слову, частотность ключевых слов (любую – базовую, “”, “!”), а также сезонность запросов. Пригодится при составлении семантического ядра онлайн.
Главное отличие нашего парсера Wordstat – отсутствие необходимости покупать прокси, антикапчи. Никаких сложных дополнительных настроек также не требуется. Здесь достаточно задать свои запросы – и вы быстро получаете готовые данные Yandex.Wordstat.
Пошаговый алгоритм работы с сервисом:
Создание задачи.
Чтобы создать задачу, необходимо перейти во вкладку Wordstat и нажать “Создать новую задачу”
Шаг первый: Поисковая система и регион.
Здесь необходимо ввести название задачи (обязательное поле). Можно ввести любое название, часто бывает удобно вводить название сайта, чтобы в будущем легко найти нужную задачу.
Выберите регион.

Шаг второй: Настройки сбора
Здесь есть два чекбокса, от выбора которых будет зависеть тип задачи:
- Сбор ключевых слов
- Сбор частотности (популярности ключевых слов)
- Проверка сезонности запросов (статистика за 2 года)
В опции “Сбор ключевых слов” вы указываете количество страниц выдачи Wordstat, по которым пройдет робот.
«Парсить страниц»: чем глубже идет робот, тем больше ключевых слов можно получить.
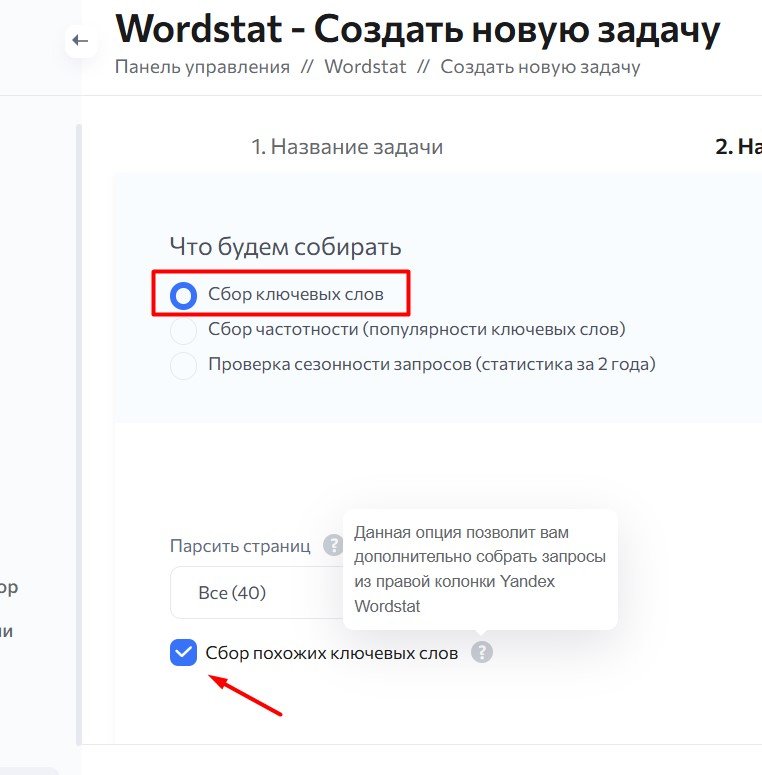
Также вы можете выбрать “Сбор похожих ключевых слов“. В таком случае вы соберете ключевые слова из левой и правой колонки Wordstat
Сбор частотности (популярности ключевых слов)
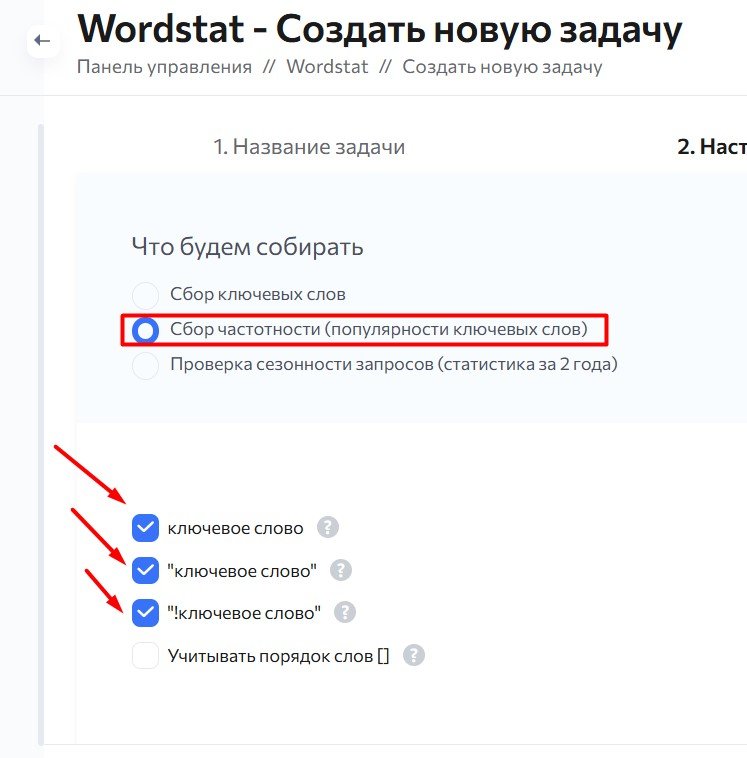
- Вы указываете необходимый вам тип частотности
В парсинге Вордстата используется умный алгоритм, он обходит ограничения в 7 слов, которое есть при парсинге через Яндекс.Директ (парсинг через Яндекс.Директ использует большинство оптимизаторов при работе в Кей Коллекторе).
Проверка сезонности запросов (статистика за 2 года)
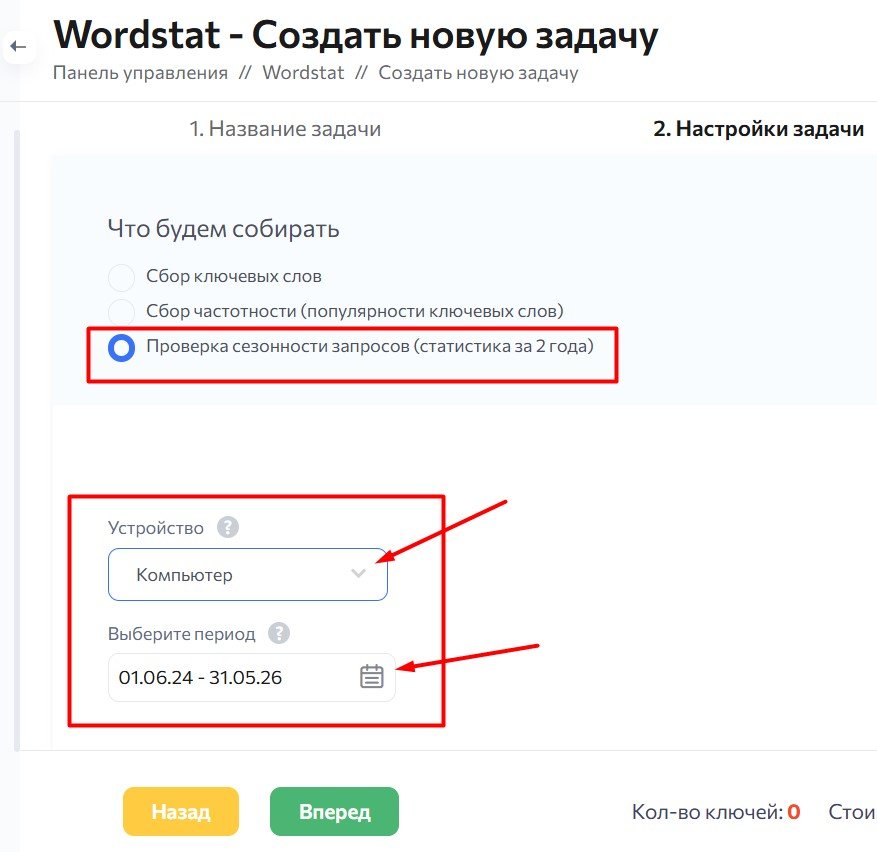
Доступны для сбора данные за последние 2 года.
При этом стоит учитывать, что за текущий месяц скорее всего данных в Яндекс Wordstat еще не будет.
Шаг третий: «Ключевые слова и цена».
Загружаем запросы.
Можно загрузить списком либо через файл. Поддерживаемые форматы файла: xls, xlsx. Необходимо указать столбец, из которого должны браться данные, а также учитывать или нет первую строку.

Функционал стоп-слов позволит отфильтровать ваш список и сэкономить время и средства. Вы можете воспользоваться готовым списком стоп-слов – выбрать стоп-слова по тематикам и нужный вам регион.
“Эксперт опции” позаботиться о том, чтобы вы не потеряли нужные слова. Обращаем внимание, что по умолчанию применяется символьное соответствие – т.е. стоп-слово “бу” удалит слова и фразы содержащие в себе сочетания букв “бу” – “бублик, бу холодильник, бумага” и т.д. Если выбрать фразовое соответствие стоп-слово “бу” удалит только слово / сочетания слов со словом “бу” – “бу холодильник, купить холодильник бу, бу”, но не “бумага, бумеранг” и т.п.

Затем нажимаем “Запустить задачу”.
Статусы задач
На странице списка задач виден статус заявки.
Очередь – данные еще не собираются.
Сбор данных – счетчик показывает, сколько ключевых слов обработано.
Готов – рядом появляется возможность скачать .xlsx файл.
Результат задачи
После завершения обработки вы можете сразу отправить файл на кластеризацию.
Экспортный файл имеет вид:

А также вы можете создать задачи по парсингу Wordstat: сбор ключевых слов, проверка частотности, сезонности через API (api wordstat yandex) – https://www.rush-analytics.ru/api
Правила оптимизации текстов на сайте — как обогнать конкурентов?
Была ли статья полезной?
 455
455
 19
19