


Дубли страниц — это одинаковые или очень похожие страницы по содержанию с разными URL адресами.
Дублированные страницы представляют серьезную проблему для владельцев веб-сайтов. В этой статье рассмотрим, как найти дубли на сайте, почему они возникают и какие методы можно использовать для их устранения. Материал будет полезен как SEO-специалистам, так и владельцам сайтов, желающим оптимизировать свой сайт.
📊 65–80% сайтов сталкиваются с проблемой дублирования
📈 До 30–50% потери трафика в зависимости от типа дублей
⏱️ 25-40% потери краулингового бюджета
🎯 Скорость индексации страниц в 2–5 раз медленнее
Что такое дубли страниц и почему они вредны
Дубли страниц – это идентичный или почти идентичный контент, доступный по разным URL-адресам. Их наличие создает несколько серьезных проблем:
- Нерациональное расходование краулингового бюджета поисковой системы.
- Каннибализация ключевиков, когда страницы конкурируют за одни запросы.
- Неэффективное распределение ссылочного веса между дублями.
- Затруднение идентификации релевантной страницы поисковыми роботами.
- Возможное попадание под фильтр Панда и другие алгоритмические санкции.
- Снижение общего качества сайта в глазах поисковых систем.
Поисковые системы стремятся экономно расходовать свои ресурсы, поэтому устанавливают для каждого сайта определенный лимит времени на сканирование. Когда роботы тратят его на дубликаты страниц, важные материалы могут остаться непроиндексированными.
Дубли страниц особенно вредны потому, что распределяют ссылочную массу между несколькими URL вместо концентрации на одной основной странице. Это критически важно, поскольку количество и качество ссылок напрямую влияет на ранжирование сайта. Дубли страниц сайта могут привести к тому, что при хорошем контенте и оптимизации, позиции сайта будут значительно ниже, чем могли бы быть.
PageRank и другие показатели, влияющие на ранжирование, “размазываются” по дублям, что снижает шансы основной страницы на хорошие позиции. Когда контентный дубль индексируется вместо основной версии, все усилия по продвижению могут оказаться напрасными, ведь в топ попадает не та страница, которую вы оптимизировали.
Дублирование контента — техническая проблема в SEO, которая сильно влияеть на краулинговые бюджеты сканирования. Когда поисковые роботы сталкиваются с несколькими версиями одного и того же контента, они тратят свои ресурсы сканирования, которые можно было бы направить на поиск и индексацию новых, ценных страниц. Источник: glorywebs.com
John Mueller руководитель отдела Google поиска
Важно понимать, что алгоритмы поисковых роботов постоянно совершенствуются и все лучше определяют дубли. Однако поисковым системам сложно самостоятельно выбрать основную версию страницы из множества дублей. Без ваших четких указаний (через редиректы или канонические ссылки) результат может быть непредсказуемым.
Виды дублей страниц
Различают два основных типа дублированного контента: дубли на одном сайте и дубли по сравнению с другими сайтами. В этой статье мы сфокусируемся на внутренних дублях, которые поисковые системы оценивают особым образом.

Полные дубликаты
Полными дубликатами считаются страницы с полностью идентичным содержимым, доступные по разным URL. Основные источники таких дублей:
- Версии с www и без www (www.site.ru vs site.ru)
- Протоколы https / http (https://site.ru vs http://site.ru)
- URL со слешем / без слеша на конце. (site.ru/about/ vs site.ru/about)
- Индексные файлы: index.html, index.php, home.html (site.ru vs site.ru/index.html)
- Страницы в верхнем и нижнем регистре (uppercase и lowercase) (site.ru/about/ vs site.ru/ABOUT/)
- Адреса с GET-параметрами и utm-метками.
Например, адрес https://site.ru и https://site.ru?utm_source= технически являются разными URL, но содержат одинаковый контент, что делает их дублем исходной страницы.
Технические дубли (www/без www, http/https, со слешем / без слеша) стоит устранить в первую очередь — они легко исправляются и дают быстрый эффект в SEO.
Частичные дубликаты
Частичными дубликатами считаются страницы с почти идентичным контентом, имеющие некоторые отличия:
- Страницы с сортировкой и фильтрацией в каталогах.
- Разновидности одного товара с разными характеристиками.
- Страниц пагинации.
- Страницы с геозависимым контентом.
Часто производители допускают ошибку, не уникализируя метатеги для таких страниц, что усиливает проблему дублирования.
Семантические дубли
Семантические дубли – это разные страницы с уникальным контентом, оптимизированные под запросы одного кластера. Для поисковых роботов они удовлетворяют один интент пользователя, что создает проблему выбора наиболее релевантной страницы для показа. Например: https://site.ru/kuhonnie-nozhi/ и https://site.ru/nozhi-dlya-kuhni
Такие дубли обычно возникают из-за неправильной группировки запросов в семантическом ядре или недостаточного контроля над содержимым сайта.
Как отличить семантический дубль от тематически близкой страницы
Чтобы определить, является ли страница семантическим дублем, проверьте:
- Степень пересечения ключевых слов (более 70% указывает на дубль).
- Присутствие одинаковых URL в выдаче по разным запросам.
- Разницу в пользовательском интенте – если посетители ищут принципиально разную информацию, страницы не являются дубликатом страницы друг друга.
Мобильная и десктопная версии: дубль или разный контент?
С внедрением Mobile-First Indexing Google начал отдавать приоритет мобильным версиям при индексации. При правильной настройке мобильная версия не считается дублем десктопной, а рассматривается как адаптация контента под другое устройство.
Для предотвращения проблем рекомендуется использовать адаптивный дизайн или четко указывать связь между версиями через специальные теги.
Откуда берутся дубли
Дубли страниц на сайте возникают по нескольким причинам:
- Технические особенности CMS, автоматически генерирующей страницы с разными URL.
- Человеческий фактор (размещение одинакового контента в разных разделах).
- Ошибки при изменении структуры сайта без настройки редиректов.
- Технические просчеты в настройке файле robots.
- Неправильная обработка URL с GET-параметрами.
Особую проблему представляют дублированного контента на сайтах электронной коммерции, где один и тот же товар может быть доступен по множеству URL-путей. Также распространенным источником дублей страниц сайта являются технические версии и тестовые поддомены, которые разработчики забывают закрыть от индексации. Нельзя недооценивать и влияние CMS с открытым исходным кодом, которые нередко генерируют дубли для обеспечения различных функций сайта.

Как изначально избежать появления дублей при создании сайта
Проще предотвратить появление дублей на этапе создания сайта, чем бороться с ними позже. Рекомендуемые превентивные меры:
- Настройка ЧПУ и логичной структуры URL.
- Использование SEO-плагинов, автоматически предотвращающих дублирование.
- Правильное планирование информационной архитектуры сайта.
- Настройка автоматического присвоения канонических URL для страниц.
- Корректная работа с GET-параметрами.

конверсии вашего сайта
в Яндекс-Директ


Уже скачали 1348 раз
Как найти дубли страниц?
Поиск дублей требует комплексного подхода. Для полной картины рекомендуется использовать несколько методов, хотя для предварительного анализа достаточно одного.
| МЕТОД ПОИСКА | СКОРОСТЬ |
| Screaming Frog | Высокая |
| Google Search Console/Яндекс Вебмастер | Средняя |
| Поисковые операторы | Низкая |
| Цитатный поиск | Низкая |
Через поисковые операторы
Самый доступный метод – использование специальных операторов в поисковиках:
- site:domain.com “уникальный фрагмент текста” – для поиска полных дублей.
- allintitle:”ключевая фраза” site:domain.com (Google) или title:”ключевая фраза” site:domain.com (Яндекс) – для проверки заголовков.
- inurl:?parameter site:domain.com – для обнаружения технических дублей с GET-параметрами.
Панели вебмастеров
Яндекс.Вебмастер
В Яндекс.Вебмастере найти информацию о дублях можно через:
- Раздел “Индексирование” → “Страницы в поиске” → “Исключенные страницы” с фильтром “Дубль”.
- Раздел “Заголовки и описания”, который показывает URL с дублирующимися метатегами.
Google Search Console
В Google Search Console проверьте:
- “Страницы” → “Не проиндексированы” → “Страница является копией. Канонический вариант не выбран пользователем”.
- Все отчеты в разделе “Почему эти страницы не индексируются”.
Цитатный поиск
Цитатный поиск подразумевает использование уникальных фрагментов текста в кавычках для поиска. Если результаты содержат несколько страниц вашего домена, значит, контент дублируется. Метод помогает обнаружить как внутренние дубли, так и случаи копирования вашего контента другими сайтами.

Автоматический поиск с помощью сервисов
Screaming Frog SEO Spider
Screaming Frog – мощный инструмент для сканирование сайта, позволяющий:
- Выявлять страницы с одинаковыми Title, Description и H1.
- Визуально сравнивать текстовое содержимое через функцию Duplicate Content.
- Анализировать контент в определенных зонах страницы.
SiteAnalyzer
SiteAnalyzer – бесплатная альтернатива Screaming Frog с ограниченными возможностями. Программа выявляет дубли по заголовкам и метатегам, но не имеет функции визуального сравнения контента.
Xenu Link Sleuth
Xenu Link Sleuth – бесплатная программа, которая выводит Title, Description и другие показатели страниц. Помогает обнаружить технические дубли, хотя и не определяет страницы с идентичным содержимым, но разными метатегами.
Rush Analytics
Аудит сайта Rush Analytics – сервис, который не только обнаруживает дубли, но и проводит полную проверку важных технических критериев. Вы получите подробный отчет о проблемах на сайте, которые могут мешать его продвижению, а также пошаговую инструкцию по их устранению.
Как убрать дубли страниц на сайте?
Устранение дублей требует разных подходов в зависимости от типа дублированного контента и возраста сайта. В большинстве случаев решение сводится к техническим настройкам.
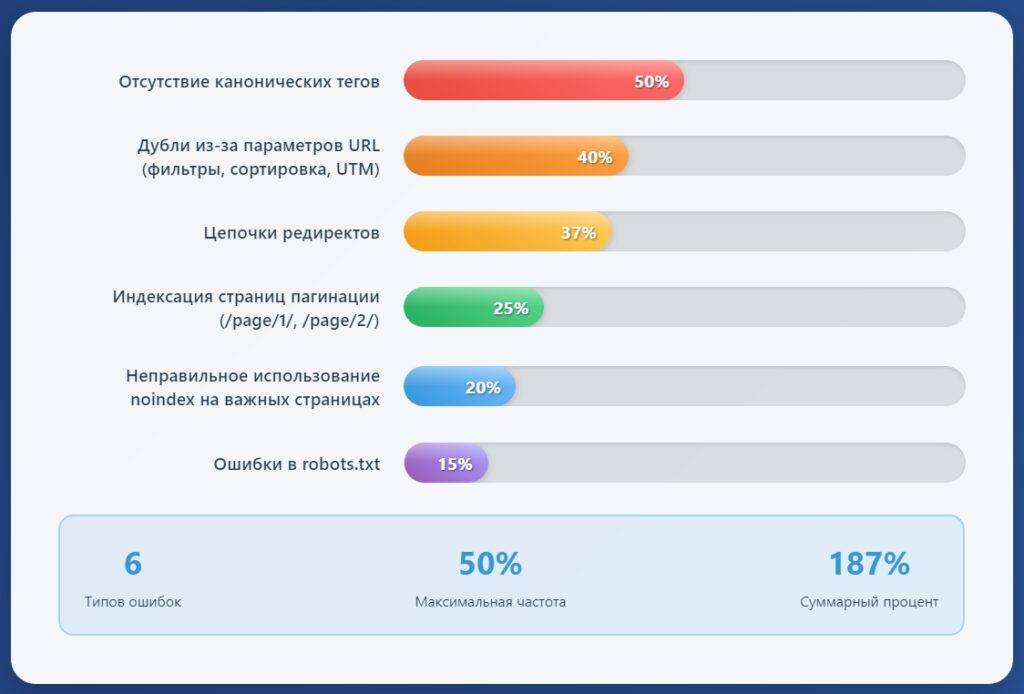
Склейка дублей через 301 редирект
301 редирект – самый надежный способ устранения полных дублей. При его использовании:
- Все метрики передаются с дублирующей страницы на основную.
- Поисковые роботы и пользователи автоматически перенаправляются на основную версию.
- Дубли постепенно удаляются из индекса (обычно в течение 1-2 недель).
Особенно эффективен для неосновных зеркал сайта, например, для склейки http и https версий.
301-редиректы — золотой стандарт решения проблем с дублированием контента. Они передают почти 100% ссылочного веса на целевую страницу и дают поисковым системам чёткие сигналы о вашей структуре URL. Однако избегайте цепочек перенаправлений длиннее трёх переходов для поддержания эффективности сканирования.
Barry Adams основатель компании Polemic Digital
Создание канонической страницы (rel=”canonical”)
Атрибутом rel=”canonical” указывает поисковым роботам, какую страницу считать основной. В дублирующую страницу добавляется код:
<link rel="canonical" href="https://site.ru/main-page" />
Преимущество метода – дубли остаются доступными для пользователей, но исключаются из индекса.
Атрибут canonical служит рекомендацией для поисковых систем, но окончательное решение о том, какая страница будет считаться канонической, принимают сами поисковые системы.
Директива Disallow в robots.txt
Директивы в robots.txt запрещают сканирование определенных URL:
User-agent: * Disallow: /*?sphrase_id=
Метод имеет ограничения: страницы могут попасть в индекс через внешние ссылки, а запрещенные к сканированию URL не передают вес основным страницам.
Настройка 404 ответа
Корректная настройка 404 ответа помогает избавиться от технических дублей, вызванных произвольными символами в URL, нарушениями вложенности и вариациями форматов. Важно, чтобы сервер действительно возвращал код 404, а не 200 с шаблоном страницы ошибки.
Физическое удаление дублей
Физическое удаление дублей подразумевает полное исключение страниц из структуры сайта и внутренней перелинковки. Подходит для статических дублей с минимальной значимостью. Перед удалением следует проанализировать трафик и ссылочный профиль страницы.
Закрытие дублей от индексации через noindex
Тег noindex запрещает индексацию страницы:
<meta name="robots" content="noindex">
Не рекомендуется как основной метод устранения дублей, поскольку не передает ссылочный вес и расходует краулинговый бюджет.
Склейка дублей через директиву Clean-param
Директива Clean-param используется только в Яндексе и указывает GET-параметры, не влияющие на содержание. Например, чтобы закрыть страницу: https://site.ru?utm_source ,необходимо указать директиву:
Clean-param: utm_source
Эффективно оптимизирует ресурсы поисковых роботов, но работает только для одной поисковой системы.
Уникализация частичных дублей
Для страниц с важными ссылками, но без потенциала привлечения трафика (например, страниц пагинации) рекомендуется:
- Добавить номер страницы в Title.
Например:
Блог – Rush Analytics (основная страница)
Блог – Rush Analytics – Page 2 Of 19 (вторая страница пагинации)
- Добавить номер страницы в Description.
- Отображать SEO-тексты только на первой странице категории.
Распространенные ошибки при устранении дублей
При работе с дубликатами страниц часто допускаются ошибки:
- Неправильное использование canonical (указание на неиндексируемые страницы).
- Создание цепочек и циклов редиректов.
- Применение противоречащих директив (например, noindex и canonical одновременно).
- Несогласованные канонические ссылки на разных страницах одной группы.
Ответы на популярные вопросы
Наказывает ли Google за дублированный контент внутри сайта?
Google официально заявляет, что не применяет санкций за наличие дубликатов страниц внутри одного домена. Алгоритмы стремятся выбрать наиболее релевантную версию контента для показа в результатах, а не наказывать за дублирование, если оно не служит цели обмана.
Страницы с разными картинками, но одинаковым текстом считаются дублями?
Да, такие страницы считаются дублями. По словам представителей Яндекса, для отдельной индексации необходимы отличия в текстовом содержимом, а не только в изображениях.
Почему разные страницы признаются дублями и исключаются из поиска?
Если страницы с разным контентом признаются дублями, это обычно связано с временными техническими ошибками, когда они возвращали одинаковое сообщение об ошибке или пустой контент. После устранения проблемы и переобхода роботами ситуация нормализуется.
Можно ли закрыть дубли через Disallow в robots.txt?
Этот метод не оптимален, поскольку дубли все равно могут попасть в индекс через внешние ссылки, а закрытые от сканирования страницы не передают вес основным. Рекомендуется использовать canonical или 301 редирект.
Достаточно ли один раз проверить дубли на сайте?
Для активно развивающегося сайта одноразовой проверки недостаточно. Рекомендуется включить поиск дублей в регулярный технический аудит сайта с периодичностью от месяца до квартала в зависимости от темпов обновления контента.
Что делать, если основное зеркало выбрано ошибочно?
Необходимо настроить 301 редиректы со страниц неверного зеркала на правильные и запустить процедуру переезда сайта в Яндекс.Вебмастере. Это поможет поисковым системам быстрее переоценить структуру сайта.
Влияют ли дубли на Core Web Vitals?
Прямой зависимости нет, но косвенное влияние может быть значительным. Распыление внутреннего ссылочного веса между дублями может замедлить улучшение метрик LCP, FID и CLS для важных страниц из-за неэффективного распределения ресурсов.
Чем отличается подход к дублям у Google и Яндекс?
Основные различия:
- Яндекс поддерживает директиву Clean-param, Google — нет.
- Google строже относится к избыточным редиректам.
- Яндекс быстрее обновляет данные о дублях в панели вебмастера.
- Различия в подходе к мобильным версиям: Google жестко придерживается Mobile-First Indexing.
Заключение
Полное устранение дублей, особенно вызванных GET-параметрами, не всегда возможно, но крайне важно исключить их из индексации. Правильная работа с дублированным контентом положительно влияет на трафик и позиции сайта.
Выбирая метод устранения, учитывайте свой уровень навыков и конкретную ситуацию. Наиболее надежен 301 редирект, но в некоторых случаях эффективнее применять canonical или другие решения. Помимо борьбы с дублями, важно комплексно оптимизировать сайт для максимального улучшения позиций в поисковых системах.








